
敏感词过滤
系统需要对用户输入的文本进行敏感词过滤如色情、政治、暴力相关的词汇。
敏感词过滤用的使用比较多的 Trie 树算法 和 DFA 算法。
算法实现
Trie 树
Trie 树 也称为字典树、单词查找树,哈系树的一种变种,通常被用于字符串匹配,用来解决在一组字符串集合中快速查找某个字符串的问题。像浏览器搜索的关键词提示一般就是基于 Trie 树来做的。

假如我们的敏感词库中有以下敏感词:
- 高清有码
- 高清 AV
- 东京冷
- 东京热
我们构造出来的敏感词 Trie 树就是下面这样的:
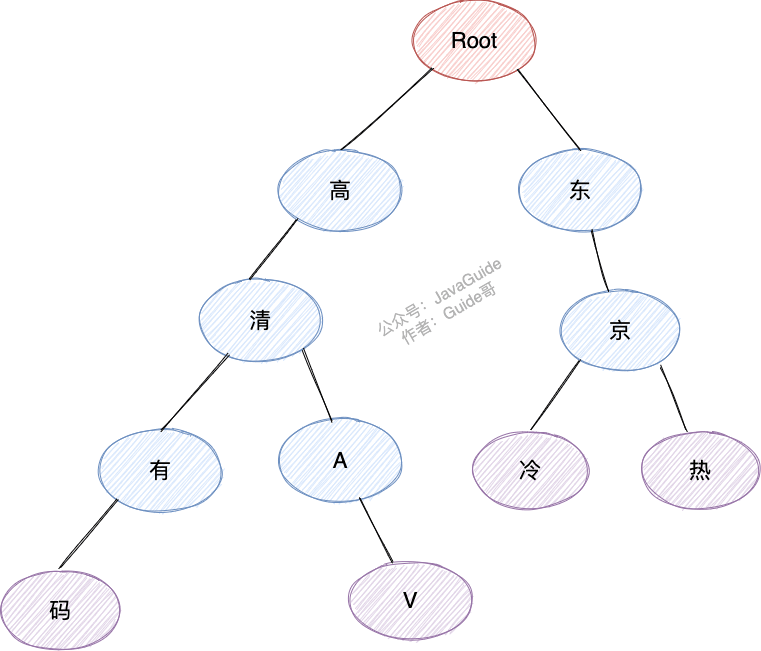
当我们要查找对应的字符串“东京热”的话,我们会把这个字符串切割成单个的字符“东”、“京”、“热”,然后我们从 Trie 树的根节点开始匹配。
可以看出, Trie 树的核心原理其实很简单,就是通过公共前缀来提高字符串匹配效率。
Apache Commons Collecions 这个库中就有 Trie 树实现:
Trie<String, String> trie = new PatriciaTrie<>();
trie.put("Abigail", "student");
trie.put("Abi", "doctor");
trie.put("Annabel", "teacher");
trie.put("Christina", "student");
trie.put("Chris", "doctor");
Assertions.assertTrue(trie.containsKey("Abigail"));
assertEquals("{Abi=doctor, Abigail=student}", trie.prefixMap("Abi").toString());
assertEquals("{Chris=doctor, Christina=student}", trie.prefixMap("Chr").toString());
Aho-Corasick(AC)自动机是一种建立在 Trie 树上的一种改进算法,是一种多模式匹配算法,由贝尔实验室的研究人员 Alfred V. Aho 和 Margaret J.Corasick 发明。
AC 自动机算法使用 Trie 树来存放模式串的前缀,通过失败匹配指针(失配指针)来处理匹配失败的跳转。
| 相关阅读:[地铁十分钟 | AC 自动机](https://zhuanlan.zhihu.com/p/146369212) |
DFA
DFA(Deterministic Finite Automata)即确定有穷自动机,与之对应的是 DFA(Non-Deterministic Finite Automata,有穷自动机)。
关于 DFA 的详细介绍可以看这篇文章:有穷自动机 DFA&NFA (学习笔记) - 小蜗牛的文章 - 知乎 。
Hutool 提供了 DFA 算法的实现:
WordTree wordTree = new WordTree();
wordTree.addWord("大");
wordTree.addWord("大憨憨");
wordTree.addWord("憨憨");
String text = "那人真是个大憨憨!";
// 获得第一个匹配的关键字
String matchStr = wordTree.match(text);
System.out.println(matchStr);
// 标准匹配,匹配到最短关键词,并跳过已经匹配的关键词
List<String> matchStrList = wordTree.matchAll(text, -1, false, false);
System.out.println(matchStrList);
//匹配到最长关键词,跳过已经匹配的关键词
List<String> matchStrList2 = wordTree.matchAll(text, -1, false, true);
System.out.println(matchStrList2);
输出:
大
[大, 憨憨]
[大, 大憨憨]
开源项目
- ToolGood.Words :一款高性能敏感词(非法词/脏字)检测过滤组件,附带繁体简体互换,支持全角半角互换,汉字转拼音,模糊搜索等功能。
- sensitive-words-filter :敏感词过滤项目,提供 TTMP、DFA、DAT、hash bucket、Tire 算法支持过滤。可以支持文本的高亮、过滤、判词、替换的接口支持。